精确关键字匹配
预期结果?
- 当用户输入问题时(例如您是否支持 WhatsApp Chatbot 解决方案?),FAQ 模块将扫描整个数据源以查看关键字组中是否存在完全匹配。
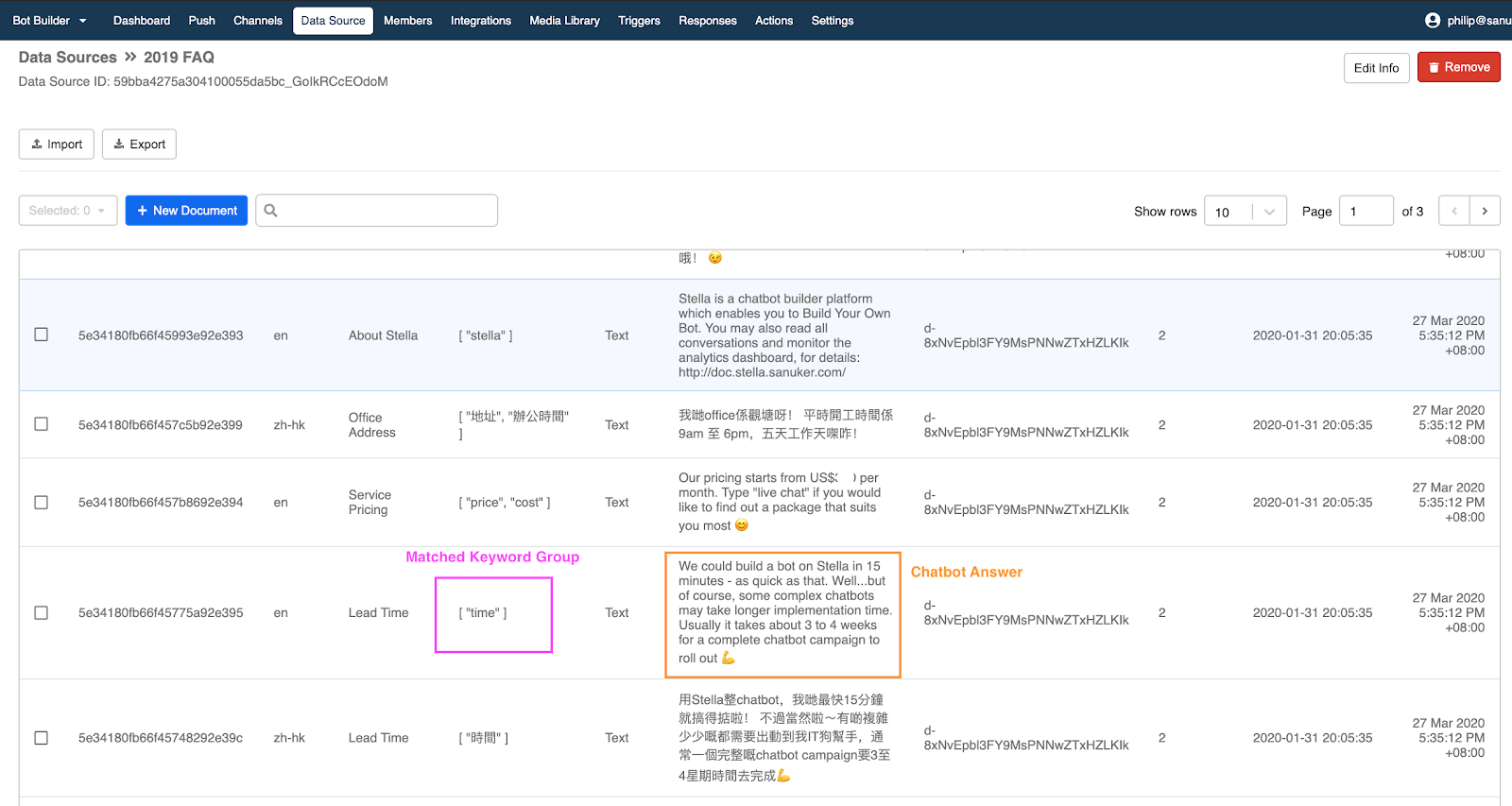
Example of FAQ Chatbot Data source
- 与FAQ条目匹配后,聊天机器人将显示相应条目的答案。 (在这种情况下,文本响应。)
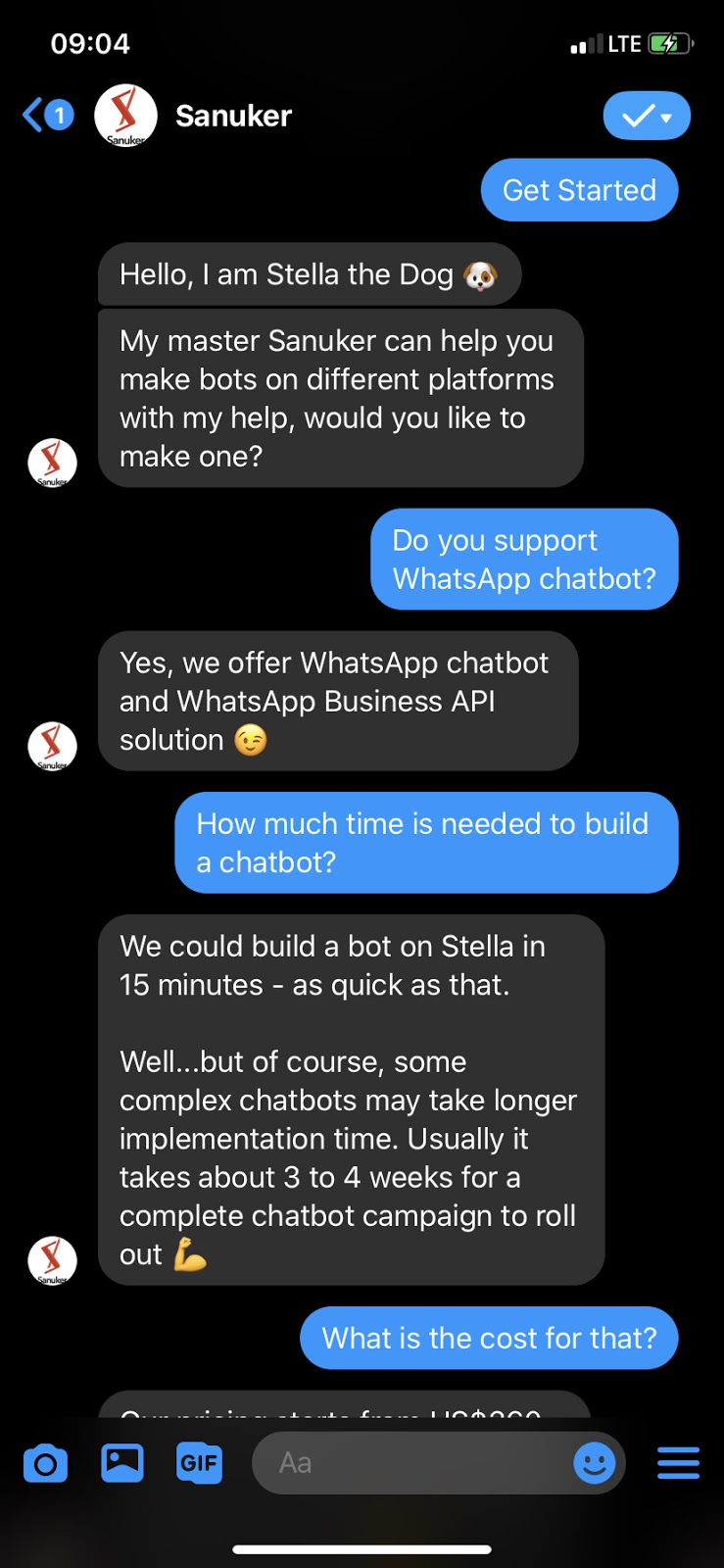
Example of FAQ Chatbot
FAQ 数据源格式
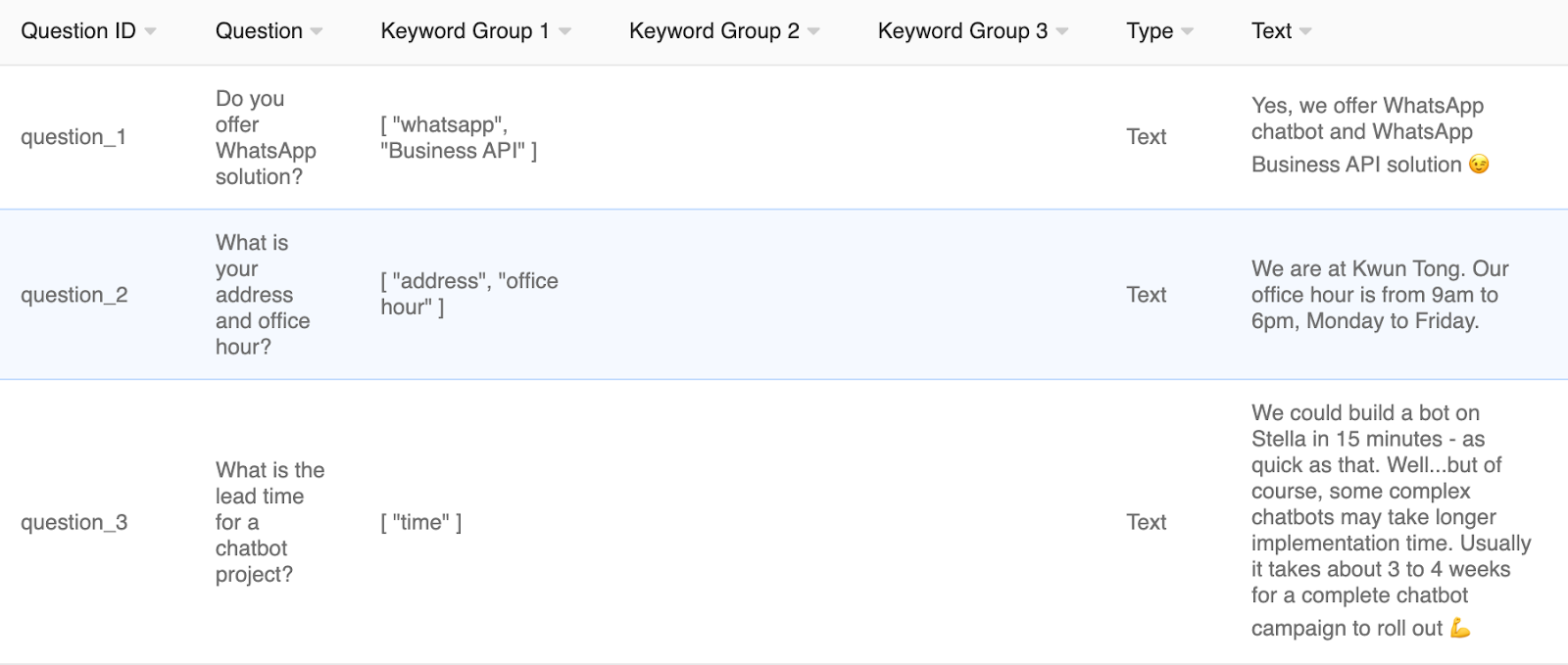
Example of FAQ Chatbot Data source
基本数据源格式应为.CSV文件格式,包括以下项目:
| 项目 | 描述 | 必需 |
|---|---|---|
| Language | "语言"是指本FAQ条目的语言。 | 第1级 |
| Category 1-3 | "类别"指的是类别1-3过滤问题上显示的选项。 | 第5级 |
| Category 1-3 Priority | 类别优先级指的是在类别1-3筛选问题上显示的选项的位置优先级(数值越低,位置越高)。 | Level 5 |
| Question ID | “问题 ID”是每个条目的唯一标识符。 | 第1级 |
| Question | “问题”仅供您在此阶段参考。这是您希望用户提出的标准示例问题。例如,“产品 A 的价格是多少?”。 但是,如果您将常见问题分类并以列表(网络聊天)或一组过滤问题(WhatsApp)或永久菜单(Facebook)的形式显示,则将显示“问题”的内容供用户选择。 | 第2级 |
| Analytics Category | 分析类别是指每个FAQ条目的独特分析标签。 | 第4.2级 |
| Analytics ID | 分析ID指的是每个FAQ条目的分析类别。 | 第4.2级 |
| Keyword Group | 关键字组由要与用户输入搜索/匹配的关键字组成。您可以输入关键字的多个变体/同义词。例如,如果您希望用户询问您产品的定价,那么将“定价”、“价格”或“成本”放入数据源中就很有意义。格式将为 [“定价”、“价格”、“成本”]。引号之间的词共享“或”关系。 您也可以为每个条目设置多个关键字。不同关键字组之间的关系是“AND”。这意味着用户的输入必须与条目的 所有关键字组 匹配,以便聊天机器人回复相应的答案。每个条目的关键字组越多,您就可以为系统提供更多上下文。 (但是,这也意味着这个条目更难触发。) 例如,如果用户询问产品A的价格,您可以将关键字组1设置为[“产品A”] & 关键字组 2 为 [“价格”]。您可以对产品 B、产品 C 做同样的事情……。产品 N。然后,每个聊天机器人的回答都将回复特定的产品。 | 第1级 |
| Intent | "意图"是指谷歌Dialogflow或微软LUIS上的NLP引擎的训练意图。 | 第4.3级 |
| Type | "类型"是你的答案的信息响应类型。对于这个标准程序,类型。支持 "文本"、"图像"、"视频"、"GIF"、"文件"、"音频 "和 "重定向"。请确保你有正确的类型。 | 第1级 |
| Text | "文本"是常见问题条目的聊天机器人文本答案。 | 第1级 |
| URL | "URL"指的是 "图像"、"视频"、"GIF"、"文件 "和 "音频 "的多媒体链接。 | 第1级 |
| Preview | "预览"指的是WhatsApp文本回复上的链接预览。设置 "TRUE"来显示预览。 | 第1级 |
| Caption | "标题"是指WhatsApp图片的标题文字。在输入标题之前,请确保 "URL"填写的是图片链接。 | 第1级 |
| treeID | "treeID"指的是Stella应该将用户重定向到的树。请确保消息类型选择 "Redirect"。 | 第4.1级 |
| compositeID | "compositeID"是指Stella应该将用户重定向到的树节点的compositeID。你可以在树节点中找到这个信息。请确保消息类型选择 "Redirect"。 | 第4.1级 |
你可以在这里下载.CSV格式的FAQ数据源样本。
动手实践
示例树结构
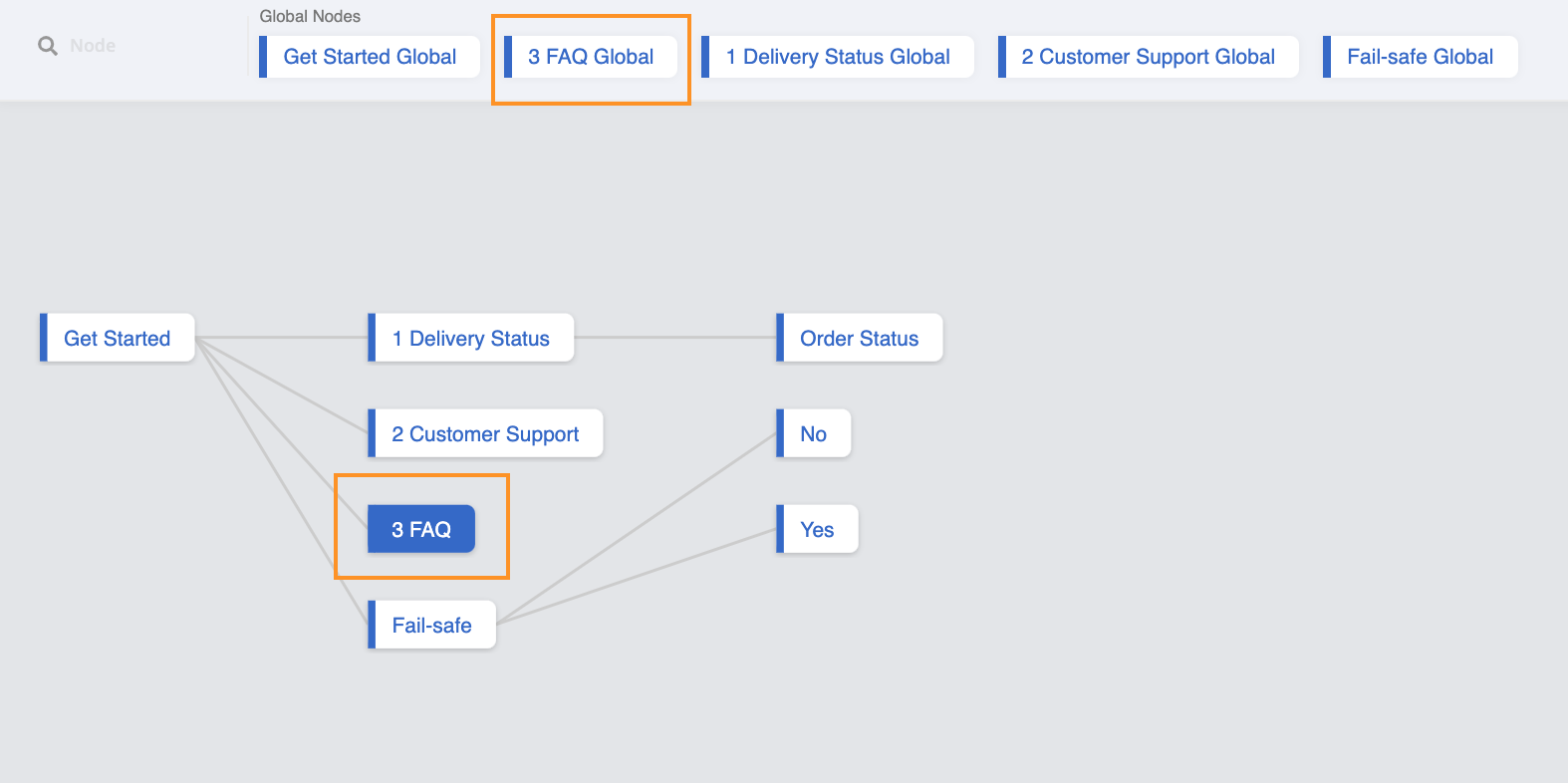
Tree Structure of FAQ Chatbot with Exact Keyword Match
创建一个新的数据源
- 前往“数据源”并选择“+新数据源”。

Add a New Data Source
- 命名您的新数据源。
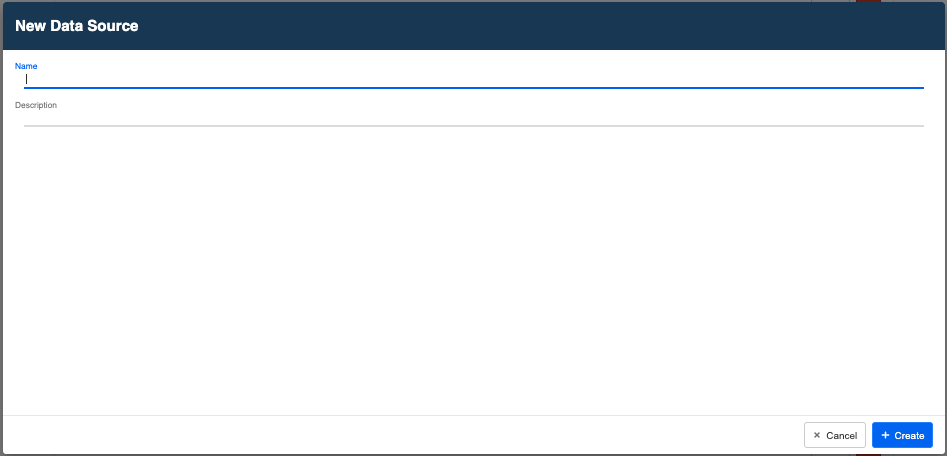
Name the New Data Source
- 通过选择文件导入您的 .CSV 文件,切换“替换”和“解析 JSON”
记住要启动 "解析JSON",以避免可能的错误。
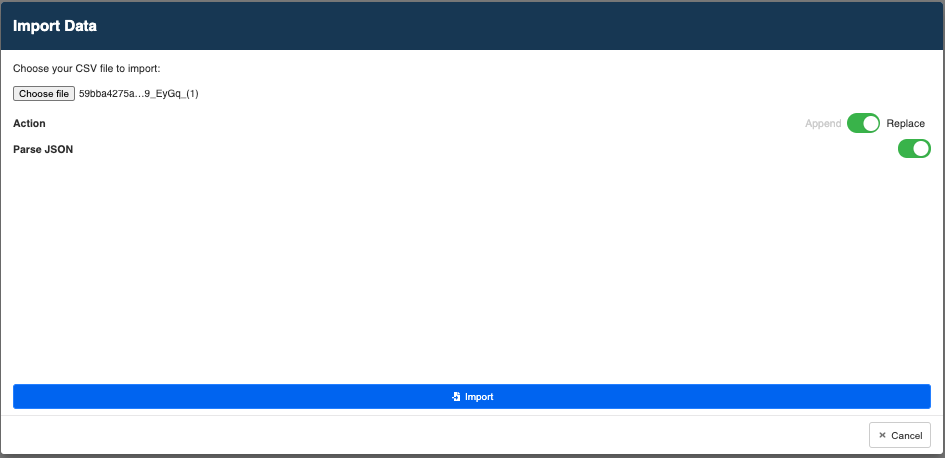
Import the Data Source File
- 复制“Data Source ID”,稍后粘贴到代码中的“collectionName”上。
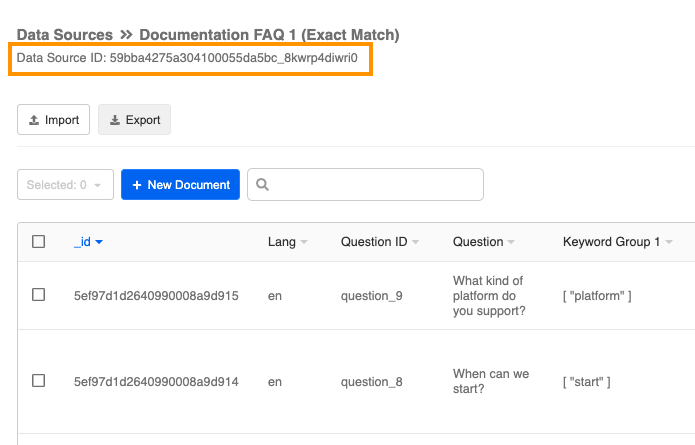
Save Data Source ID
为 FAQ 模块创建一个树节点
- 前往一棵树并为 FAQ 模块创建一个 树节点。
6.在这个树节点中创建一个pre-action(这是为了处理精确的关键字匹配逻辑),使用以下代码(记得将Data Source ID应用于collectionName 代码):
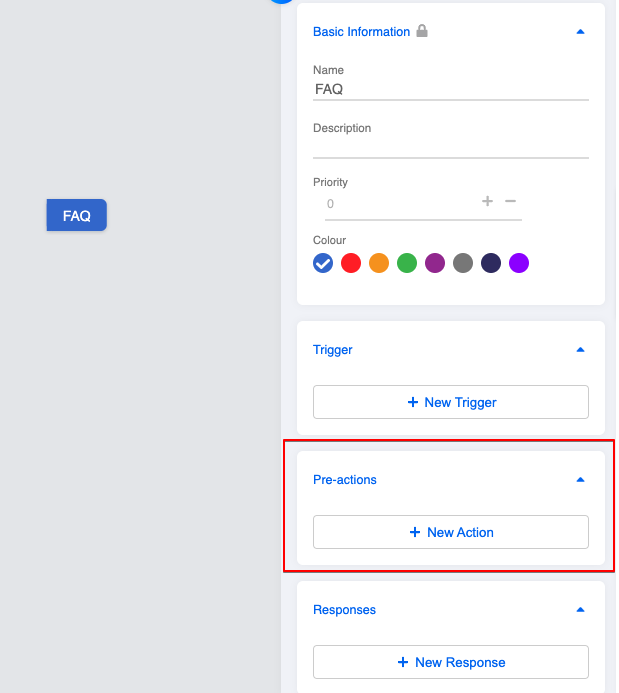
Create Pre-actions
return new Promise((resolve, reject) => {
console.log("in Save FAQ temp ans")
let text = this.messageEvent.data.text
text = text.replace(/\r\n|\r|\n/g, "")
text = text.replace(/(\/|\.|\*|\?|\+)/g, "")
function genKeywordsRegex(keywords, text) {
// return "/(" + keywords.join("|") + ")/i.test('" + text + "')"
let regex = new RegExp("(" + keywords.join("|") + ")", "i")
return regex.test(text)
}
this.fetchDataFromDataSource({
collectionName: "enter the Data Source ID here",
filter: {}
}).then((result) => {
console.log("length", result.length);
const ans = result.filter((doc) => {
if (this.lodash.isArray(doc["Keyword Group 1"]) && this.lodash.get(doc, "Keyword Group 1.length") && this.lodash.isArray(doc["Keyword Group 2"]) && this.lodash.get(doc, "Keyword Group 2.length") && this.lodash.isArray(doc["Keyword Group 3"]) && this.lodash.get(doc, "Keyword Group 3.length") ) {
const regex1 = genKeywordsRegex(doc["Keyword Group 1"], text)
const regex2 = genKeywordsRegex(doc["Keyword Group 2"], text)
const regex3 = genKeywordsRegex(doc["Keyword Group 3"], text)
console.log("current doc (3 keyword group)", doc["Question ID"])
return regex1 && regex2 && regex3
} else if (this.lodash.isArray(doc["Keyword Group 1"]) && this.lodash.get(doc, "Keyword Group 1.length") && this.lodash.isArray(doc["Keyword Group 2"]) && this.lodash.get(doc, "Keyword Group 2.length")) {
const regex1 = genKeywordsRegex(doc["Keyword Group 1"], text)
const regex2 = genKeywordsRegex(doc["Keyword Group 2"], text)
console.log("current doc (2 keyword group)", doc["Question ID"])
return regex1 && regex2
} else if (this.lodash.isArray(doc["Keyword Group 1"]) && this.lodash.get(doc, "Keyword Group 1.length")) {
const regex1 = genKeywordsRegex(doc["Keyword Group 1"], text)
console.log("current doc (1 keyword group)", doc["Question ID"])
return regex1
} else {
return false
}
})
console.log("ans", ans)
this.lodash.set(this.member, "botMeta.tempData.faqAns", [])
this.lodash.set(this.member, "botMeta.tempData.faqAns", ans)
// this.member.botMeta.tempData.faqAns = ans
resolve({ member: this.member })
})
})
7.在这个树节点的“Advanced”中创建一个transformed响应,用于显示基于匹配条目的聊天机器人答案,代码如下:
Transform Response
return new Promise((resolve, reject) => {
console.log("in FAQ Keyword")
let ans = this.member.botMeta.tempData.faqAns || []
console.log("ans", ans)
if (ans.length >= 1) {
let response = {}
switch (ans[0].Type) {
case "Text":
response.type = "TEXT"
response.text = ans[0].Text
if (ans[0].Preview === true || ans[0].Preview === "TRUE") {
response.preview_url = true
}
break
case "Image":
case "Image_Text":
response.type = "IMAGE"
response.url = ans[0].URL
response.text = ans[0].Text
break
case "Video":
case "GIF":
case "File":
response.type = "FILE"
response.url = ans[0].URL
response.text = ans[0].Text
response.filename = ans[0]["File Name"]
break
case "Audio":
response.type = "AUDIO"
response.url = ans[0].URL
break
default:
response = null
break;
}
resolve(response)
} else {
resolve({
type: "TEXT",
text: "Sorry, we don't have the answer for you at the moment. You may try to ask us in another way or reach our support team at hello@sanuker.com."
})
}
})
为 FAQ 模块创建一个全局节点
8.创建一个全局节点,用于触发同一树中的FAQ模块。
- 在 global node 中创建一个 trigger,预定义触发器为“Any Text”。
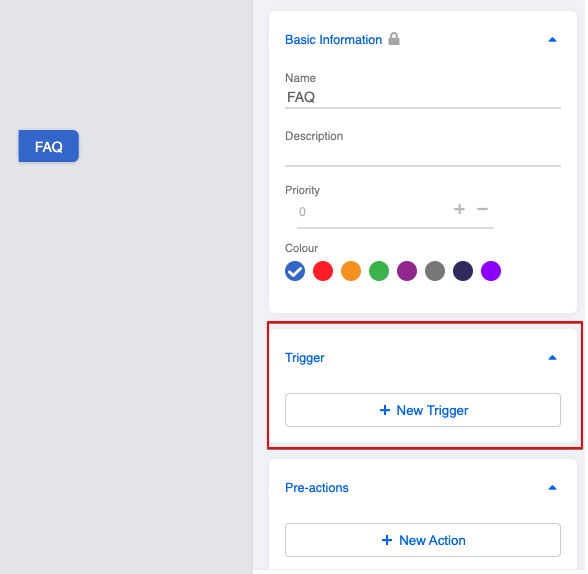
Create Trigger
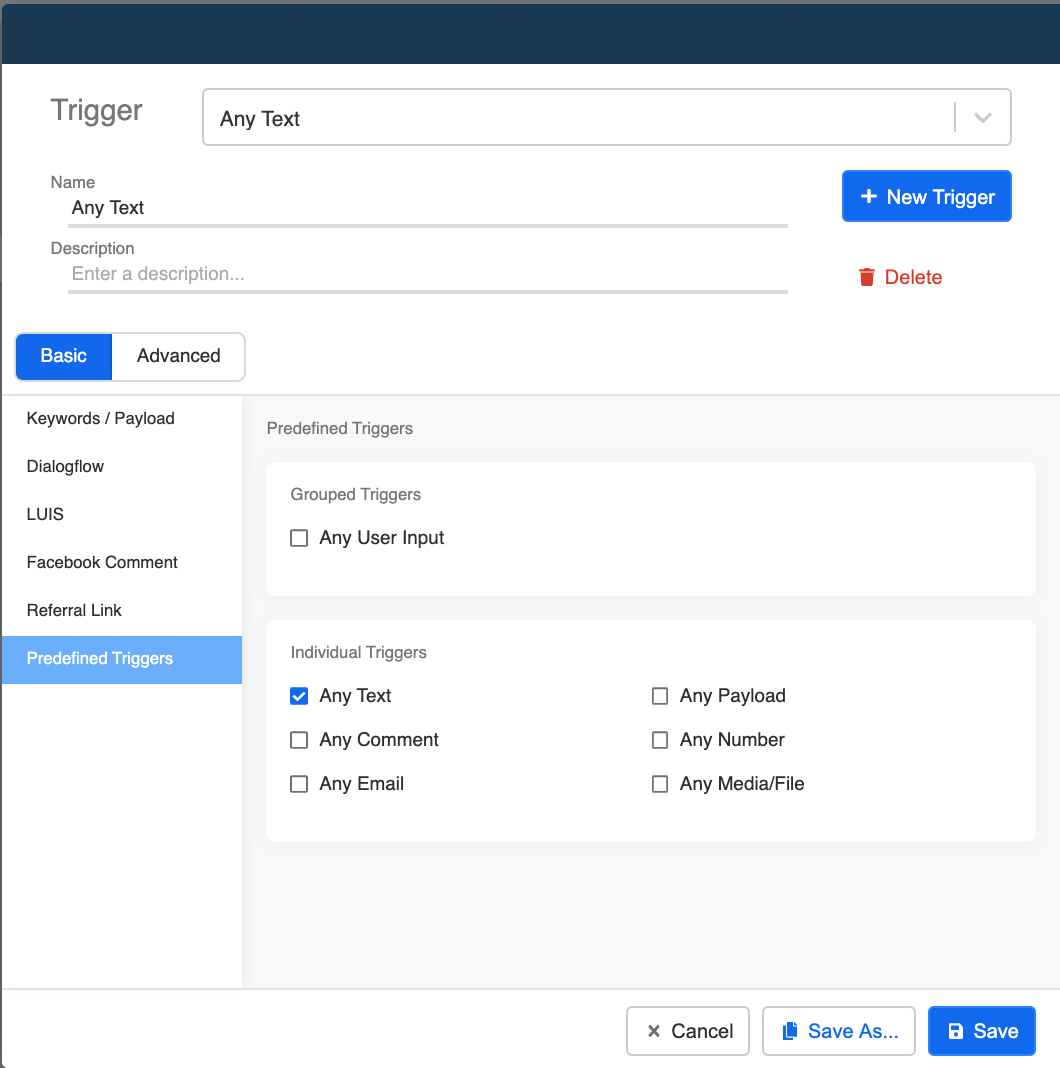
Create "Any Text" Trigger
- 切换重定向到您创建的常见问题树节点并保存此全局节点。
将树添加到通道中
树完成后,前往 "频道"。
找到你想部署树的频道,点击 "编辑"。
Channels
前往 "平台",然后是 "树设置"。
选择 "+新树",并从下拉菜单中挑选树,记得也要选择全局节点。之后,选择 "保存",完成添加树到通道。
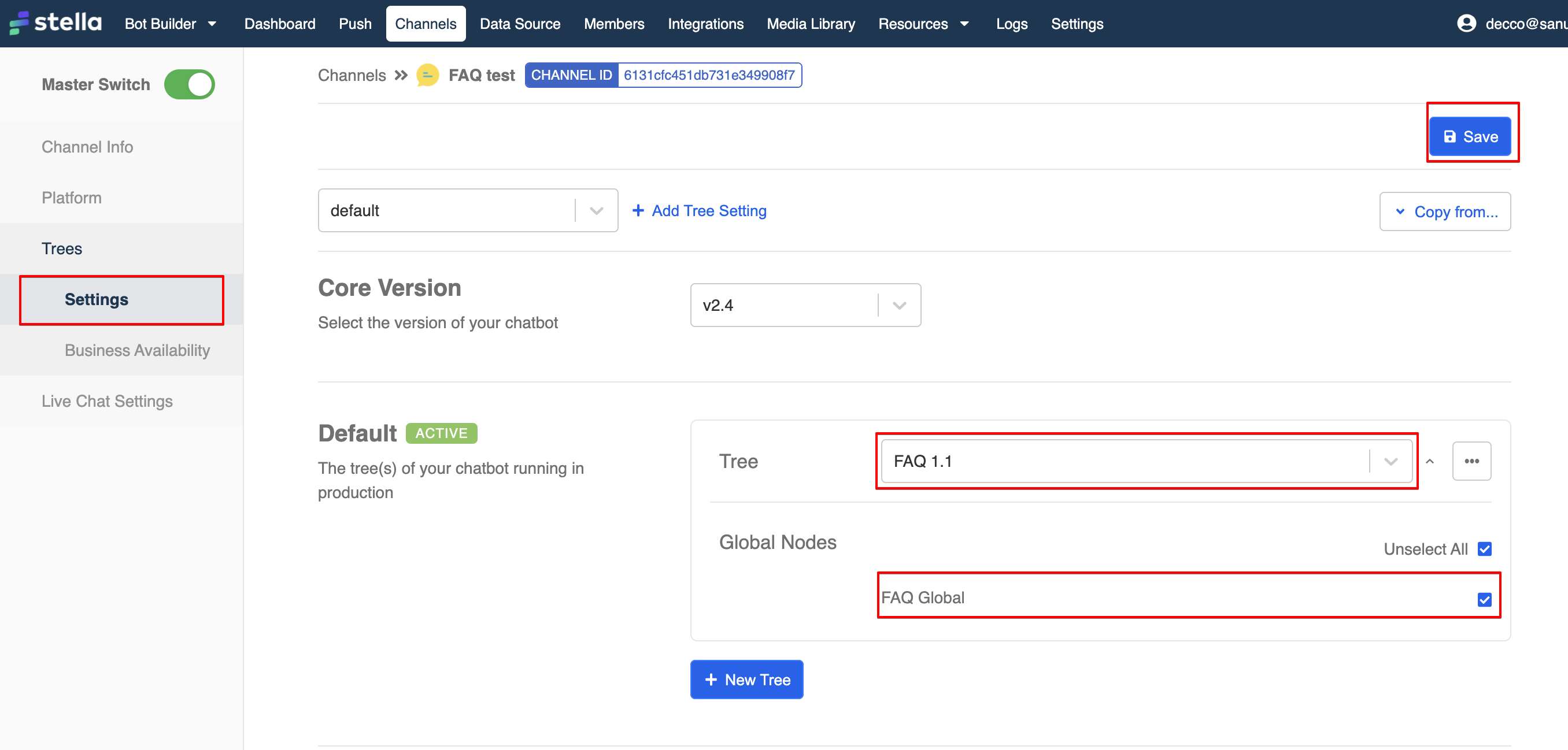
Add Trees
请记住,在建造完其他级别的常见问题树后,重复步骤11-14,把树添加到频道。
检查您是否可以产生预期结果。